Introduction
Indexes are the secret sauce behind blazing-fast database queries, but not all indexes are created equal. Clustered and non-clustered indexes work differently, and knowing when to use each can make or break your database performance.
In this guide, we’ll break down the difference between these two types of indexes in a way that makes sense—even if you’re new to databases. From their quirks to their real-world applications, you’ll learn how they work, when to use them, and the trade-offs that come with each.
Ready to turn your queries into speed demons? Let’s dive in!
Clustered Index
- What it does: Rearranges the entire table based on the indexed column. The table itself becomes a sorted haystack.
- Example: Your
userstable’sid(primary key) is the default clustered index in most databases. The data is stored in order ofid, like a bookshelf sorted by ISBN.
Database-Specific Clustered Index Implementations
MySQL (InnoDB)
- Primary key is the clustered index.
- If no primary key, the first
NOT NULLunique key becomes the clustered index. - If no valid unique key, a hidden system column (
row_id) is used:row_idis a 6-byte integer, auto-incremented per row.- Unique only within the table.
PostgreSQL
- No direct clustered index concept.
- Uses
CLUSTERcommand to physically reorder the table. - Indexes are always non-clustered.
Key Recommendation
Always consult your database’s docs—implementations vary wildly!
Non-Clustered Index
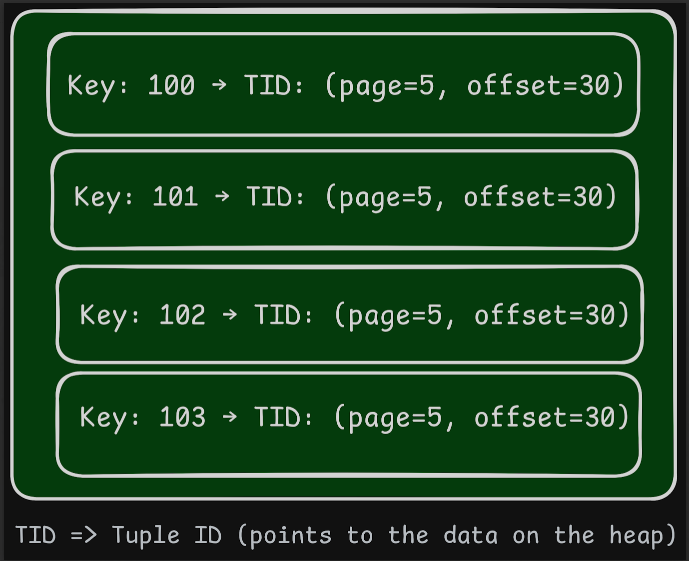
- What it does: Creates a separate structure (B-tree) that points to the actual data. The haystack stays messy, but the cheat sheet tells you where to find the hay.
- Example: Indexing username:
sql CREATE INDEX idx_users_username ON users(username); -- Non-clustered index
- Why it’s chaotic
- You can create dozens of these, but writes slow down like a turtle.
- Double the work: Queries check the B-tree first, then jump to the actual data.
Key Differences (Because You’ll Forget)
| Clustered Index | Non-Clustered Index |
|---|---|
| The table IS the index. | The index is separate. |
| Dictates physical order. | Points to data like a GPS. |
| One per table. | Unlimited (like your bad decisions). |
Faster for range queries (e.g., BETWEEN). |
Faster for single lookups. |
When to Use Which (Or Else) 🚨
- Clustered Index:
- Use for columns you query in ranges (e.g.,
id, dates).
- Use for columns you query in ranges (e.g.,
- Non-Clustered Index:
- Use for columns you filter/search frequently (e.g.,
username,email).
- Use for columns you filter/search frequently (e.g.,
What happens:
- Clustered index: Grabs data directly—table is sorted by
id. - Non-clustered index: Checks the B-tree, finds the
id, then fetches data from the heap.
Trade Offs
- Clustered Index Inserts: Inserting a row with a mid-table
idforces the database to shift data physically—like cutting in line at a concert. - Non-Clustered Index Updates: Changing a
username? The database must update both the table AND the index.
TL;DR
- Clustered Index = The table is physically sorted.
- Non-Clustered Index = A map pointing to the data’s location.
- Use both, but don’t go overboard!
Conclusion
That’s it. This article outlined the pros and cons of clustered and non-clustered index, and when to use which.
This article was written by Ahmad Adel . Ahmad is a freelance writer and also a backend developer.
