Introduction

If you're anything like me, then you're probably afraid of getting anywhere near any new topic that seems even a little bit complicated. As someone who has been traumatized MYSELF by the Node.js ecosystem and its two million packages, I can tell you—it’s a great feeling to get your hands dirty with a well-established technology. Everything feels like it belongs where it should be.
It's complicated, yes, but it's organized, and you can find your way. Yes, it will take time, but you'll get there. Databases are built by really smart people—I mean, PhD-level smart. Some of them have spent their entire lives making just a tiny contribution.
So yeah, it’s hard, it’s frustrating, but life isn’t easy.
If you are scared…. don't, there is no magic behind the scenes. It's all "RECURSION", "IF STATEMENTS", "READING FILES" and "WRITING TO FILES" , nothing more.
NOW, buckle up database adventurers! 👋 We've previously navigated the twisty paths of indexes in PostgreSQL, remember? We talked about clustered, non-clustered, and all the magic they bring to speeding up your queries. But today, we're zooming out! We're going to look at the bigger picture, the whole database neighborhood if you will. We're diving into Database Clusters in PostgreSQL! Now, hold on a sec, because the term can be a little… misleading at first glance.
Misconception about database clustering!
Think of it this way: when you hear "database cluster" you might imagine a bunch of servers all working together in a super cool, high-tech way, right? Like, a cluster of database servers. And that can be a thing in the wider database world, but in PostgreSQL land, that’s not what we're talking about. Nope! In PostgreSQL-speak, a "database cluster" is actually just a collection of databases managed by a single PostgreSQL server instance. Mind. Blown. A little counterintuitive, right? It tripped me up at first too! 😉
So, forget those images of server farms for a moment. Instead, picture a cozy apartment building. That building? That’s your PostgreSQL server! And inside that building, you have different apartments – each one is a database. Each apartment is its own self-contained unit, with its own furniture, its own… well, data! But they all exist within and are managed by the same apartment building (the server). Get it? That’s a PostgreSQL database cluster in a nutshell.
Essentially, a PostgreSQL database cluster is just a fancy way of saying all the databases managed by one PostgreSQL server. It’s the umbrella term for the whole shebang within a single server installation. Each database inside this cluster is independent – they don't automatically share data or anything like that (unless you explicitly set that up, of course, but that’s a story for another day!). But they are all living under the same roof, managed by the same PostgreSQL engine.
Postgres from inside
Catalogs, in PostgreSQL, are like the internal filing system, the index, the metadata storage that PostgreSQL uses to understand and manage everything within its “database cluster” They are essentially system tables, but we often call them catalogs, and they live in the pg_catalog schema. Think of them as special files where PostgreSQL keeps super important data about your databases, about the server itself, and everything it's managing.
These catalogs are vital. Seriously, vital. Without them, PostgreSQL would be utterly lost! It wouldn't know what databases exist, what tables are in those databases, what columns are in those tables, or even what kind of data to expect. They are the backbone of PostgreSQL’s knowledge of itself and its data structures. They are like the brain and nervous system of your database server! Dramatic, maybe, but definitely true! 😄
And guess what? Just like we have different kinds of books in a library, we have different kinds of catalogs in PostgreSQL, each responsible for storing specific types of information. Let’s peek at a few of the VIP catalogs, the rockstars of the catalog world that were mentioned:
- pg_database: As you might guess from the name, this catalog is all about… databases! It's like the directory of databases in our apartment building. pg_database stores information about each database in the cluster. Things like the database name, its encoding (like UTF-8), its owner, and various other properties. PostgreSQL uses this catalog to know which databases exist and how they are configured. Want to see it in action? You can actually query these catalogs just like regular tables! Try running SELECT datname FROM pg_database; in your psql prompt – you’ll see a list of your databases!
Check out the official docs for all the nitty-gritty details
- pg_class: Now, pg_class is a bit broader. It’s like the main index for all sorts of “classes” or “relations” within your database. And “class” here is a PostgreSQL term for pretty much anything that has a name and a type. So, what kind of "classes" are we talking about? We're talking tables, indexes, sequences, views, materialized views, and even the system catalogs themselves are in pg_class! It's a master list of all the named objects in your database system. If you want to find out if a table exists, or what type of object something is, pg_class is the place to look.
Dive deeper here.
- pg_index: We can't talk about databases without talking about indexes, right? 😉 And guess what, there’s a catalog specifically for them! pg_index stores information about… you guessed it, indexes! It tells PostgreSQL which indexes exist, which table they are on, which columns they index, and what type of index it is (btree, hash, etc.). Basically, everything PostgreSQL needs to know about your indexes to use them effectively.
- pg_sequence: And last but not least in our little catalog tour, we have pg_sequence. This one is dedicated to sequences. Sequences are those handy objects that generate automatically incrementing numbers, perfect for primary keys and unique identifiers. pg_sequence keeps track of the current value, increment step, and other properties of each sequence in your databases.
You can read more about pg_sequence here.
These four are just scratching the surface, folks! PostgreSQL has many, many more catalogs, 65 of them to be specific.
$PGDATA, where everything lives
Now, let’s get a bit more practical. What happens when you actually create a new database? Well, PostgreSQL gets to work! One of the things it does is create a new directory within the main PostgreSQL data directory, which is usually pointed to by the environment variable $PGDATA.
Think of $PGDATA as the main filing cabinet for our library. Inside $PGDATA, PostgreSQL creates a subdirectory for each database in your cluster. So, if you have databases named database_1, database_2, database_3, and database_4, your $PGDATA directory might look something like this (simplified!)
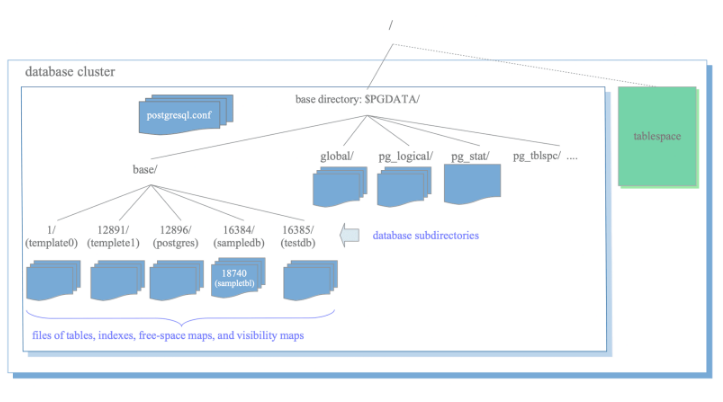 The base subdirectory within $PGDATA is particularly important. Inside base, you'll find directories with numbers as names. These numbers are actually the OID (Object Identifiers) of your databases! Remember pg_database? That's where these OIDs are tracked! When you create a new database, PostgreSQL assigns it a new OID, creates a corresponding directory under base (named with that OID), and updates the pg_database catalog to reflect this new database. It's all connected!
The base subdirectory within $PGDATA is particularly important. Inside base, you'll find directories with numbers as names. These numbers are actually the OID (Object Identifiers) of your databases! Remember pg_database? That's where these OIDs are tracked! When you create a new database, PostgreSQL assigns it a new OID, creates a corresponding directory under base (named with that OID), and updates the pg_database catalog to reflect this new database. It's all connected!
Tablespaces
Finally, let's touch briefly on Tablespaces. We said databases are stored under $PGDATA, right? Well, tablespaces are a bit of an exception, or rather, they offer flexibility! Tablespaces are any PostgreSQL-related directory that is not under the main $PGDATA directory. They are essentially alternative storage locations for your database objects (tables, indexes, etc.)
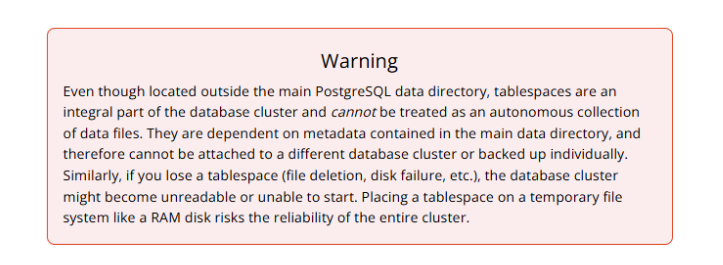 Why use tablespaces? Maybe you want to put some really performance-critical tables on faster storage (like SSDs) while keeping less frequently accessed data on cheaper, larger disks. Or perhaps you're running out of space in your default $PGDATA location and need to spread your data across multiple drives. Tablespaces are your answer! They give you more control over where your database data physically resides.
Why use tablespaces? Maybe you want to put some really performance-critical tables on faster storage (like SSDs) while keeping less frequently accessed data on cheaper, larger disks. Or perhaps you're running out of space in your default $PGDATA location and need to spread your data across multiple drives. Tablespaces are your answer! They give you more control over where your database data physically resides.
Conclusion
So, there you have it! A whirlwind tour of PostgreSQL Database Clusters, Catalogs, and a peek into $PGDATA and tablespaces. Understanding these core concepts really unlocks a deeper understanding of how PostgreSQL manages your data. It's like understanding the blueprints of that apartment building – suddenly, everything makes a lot more sense! Keep exploring, keep asking questions, and happy database-ing! 🚀
This article was written by Ahmad Adel . Ahmad is a freelance writer and also a backend developer.
